Scraping data is all the rage nowadays. But what many don’t know is that you don’t need to be a fancy hacker to be able to collect data from websites. In fact, you don’t even need any coding skills.
A multitude of tools such as browser extensions exist to alleviate the required technical knowledge. But even if that’s one hurdle too far for you, do not worry. Google will come to the rescue. Google Sheets to be precise.
It has a nifty little formula which allows you to grab a web page’s list or table of data into your sheet of choice. It’s called importhtml, and it works as follows:
As you can see, you’ll have to declare three things in the formula: The url you want to grab data from, the type of data (either table or list), and the position (in this case the second table, so 2).
Hit enter, and voilà, the table appears in your sheet:
To go next level, and actually transform or clean that data, make sure that it becomes static instead of linked data first. To do so, select the table, right mouse click on cell A1, ‘Paste special’ > ‘Paste values only’.
So there you go, have fun playing with data in Google Sheets!
Learn what Dependency Injection and IoC are and what .NET Core provides you to support them.
Dependency Injection is one of the most known techniques that help you to create more maintainable code. .NET Core provides you with extensive support to Dependency Injection, but it may not always be clear how to apply it. This tutorial will try to clarify the various Dependency Injection concepts and will introduce you to the support provided by .NET Core.
The Dependency Problem
Have you ever had to change a lot of code because of a new simple requirement? Have you ever had a hard time trying to refactor part of an application? Have you ever been in trouble writing unit tests because of components that required other components?
If you answered yes to any of these questions, maybe your codebase suffers from dependency. It’s a typical disease of the code of an application when its components are too coupled. In other words, when a component depends on another one in a too-tight way. The main effect of component dependency is the maintenance difficulty of the code, which, of course, implies a higher cost.
A dependency example
Take a look at a typical example of code affected by dependency. Start by analyzing these C# classes:
using System;
using System.Collections.Generic;
namespace OrderManagement
{
public class Order
{
public string CustomerId { get; set; }
public DateTime Date { get; set; }
public decimal TotalAmount { get; set; }
public List<OrderItem> Items { get; set; }
public Order()
{
Items = new List<OrderItem>();
}
}
public class OrderItem
{
public string ItemId { get; set; }
public decimal Quantity { get; set; }
public decimal Price { get; set; }
}
}
This code defines two classes, Order and OrderItem, that represent the order of a customer. The orders are managed by the OrderManager class implemented as follows:
using System.Threading.Tasks;
namespace OrderManagement
{
public class OrderManager
{
public async Task<string> Transmit(Order order)
{
var orderSender = new OrderSender();
return await orderSender.Send(order);
}
}
}
The OrderManager class implements the Transmit() method, which sends the order to another service to process. It relies on the OrderSender class to actually send the order received as an argument.
This is the code implementing the OrderSender class:
using System.Net.Http;
using System.Text;
using System.Text.Json;
using System.Threading.Tasks;
namespace OrderManagement
{
public class OrderSender
{
private static readonly HttpClient httpClient = new HttpClient();
public async Task<string> Send(Order order)
{
var jsonOrder = JsonSerializer.Serialize<Order>(order);
var stringContent = new StringContent(jsonOrder, UnicodeEncoding.UTF8, "application/json");
//This statement calls a not existing URL. This is just an example...
var response = await httpClient.PostAsync("https://mymicroservice/myendpoint", stringContent);
return response.Content.ReadAsStringAsync().Result;
}
}
}
As you can see, the Send() method of this class serializes the order and send it via HTTP POST to a hypothetical microservice that will process it.
The code shown here is not meant to be realistic. It is just a rough example.
What happens if you need to change the way of sending an order? For example, suppose you also want to send orders via e-mail or to send them to another microservice that uses gRPC instead of HTTP. Also, how comfortable do you feel to create a unit test for the OrderManager class?
Since OrderManager depends on OrderSender, you will be forced to change in some way both classes to support multiple sender types. Changes in the lower-level component (OrderSender) may affect the higher-level component (OrderManager). Even worse, it will be almost impossible to automatically test the OrderManager class without risking to mess your code.
This is just a simple study case. Think of the impact that dependency may have in a more complex scenario with many dependent components. That could really become a huge mess.
The Dependency Inversion Principle
The last of the SOLID principles proposes a way to mitigate the dependency problem and make it more manageable. This principle is known as the Dependency Inversion Principle and states that:
High-level modules should not depend on low-level modules. Both should depend on abstractions
Abstractions should not depend on details. Details should depend on abstractions.
You can translate the two formal recommendations as follows: in the typical layered architecture of an application, a high-level component should not directly depend on a lower-level component. You should create an abstraction (for example, an interface) and make both components depend on this abstraction.
Translated in a graphical way, it appears as shown by the following picture:
Of course, all of this may seem too abstract. Well, this article will provide you with examples to clarify the concepts about dependency and the techniques to mitigate it. While the general concepts are valid for any programming language and framework, this article will focus on the .NET Core framework and will illustrate the infrastructure it provides you to help in reducing component dependency.
A trip in the dependency lingo
Before exploring what .NET provides you to fight the dependency disease of your code, it’s necessary to put some order in the terminology. You may have heard many terms and concepts about code dependency, and some of them seem to be very similar and may have been confusing. Well, here is an attempt to give a proper definition of the most common ones:
Dependency Inversion Principle: it’s a software design principle; it suggests a solution to the dependency problem but does not say how to implement it or which technique to use.
Inversion of Control (IoC): this is a way to apply the Dependency Inversion Principle. Inversion of Control is the actual mechanism that allows your higher-level components to depend on abstraction rather than the concrete implementation of lower-level components.Inversion of Control is also known as the Hollywood Principle. This name comes from the Hollywood cinema industry, where, after an audition for an actor role, usually the director says, don’t call us, we’ll call you.
Dependency Injection: this is a design pattern to implement Inversion of Control. It allows you to inject the concrete implementation of a low-level component into a high-level component.
IoC Container: also known as Dependency Injection (DI) Container, it is a programming framework that provides you with an automatic Dependency Injection of your components.
Dependency Injection approaches
Dependency Injection is maybe the most known technique to solve the dependency problem.
You can use other design patterns, such as the Factory or Publisher/Subscriber patterns, to reduce the dependency between components. However, it mostly derives on the type of problem your code is trying to solve.
As said above, it is a technique to providing a component with its dependencies, preventing the component itself from instantiating by themselves. You can implement Dependency Injection on your own by creating instances of the lower-level components and passing them to the higher-level ones. You can do it using three common approaches:
Constructor Injection: with this approach, you create an instance of your dependency and pass it as an argument to the constructor of the dependent class.
Method Injection: in this case, you create an instance of your dependency and pass it to a specific method of the dependent class.
Property Injection: this approach allows you to assign the instance of your dependency to a specific property of the dependent class.
.NET Core and the Dependency Injection
You can implement Dependency Injection manually by using one or more of the three approaches discussed before. However, .NET Core comes with a built-in IoC Container that simplifies Dependency Injection management.
The IoC Container is responsible for supporting automatic Dependency Injection. Its basic features include:
Registration: the IoC Container needs to know which type of object to create for a specific dependency; so, it provides a way to map a type to a class so that it can create the correct dependency instance.
Resolution: this feature allows the IoC Container to resolve a dependency by creating an object and injecting it into the requesting class. Thanks to this feature, you don’t have to instantiate objects manually to manage dependencies.
Disposition: the IoC Container manages the lifetime of the dependencies following specific criteria.
You will see these features in action in a while. But before this, some basic information is needed.
The .NET Core built-in IoC Container implements the IServiceProvider interface. So if for some reason, you want to create your own IoC Container, you should implement this interface. In .NET Core, the dependencies managed by the container are called services. You have two types of services:
Framework services: these services are part of the .NET Core framework; some examples of framework services are IApplicationBuilder, IConfiguration, ILoggerFactory, etc.
Application services: these are the services that you create in your application; since the IoC doesn’t know them, you need to register them explicitly.
Dealing with Framework Services
As a .NET Core developer, you’ve already used the built-in IoC Container to inject framework services. Indeed, .NET Core heavily relies on it. For example, the Startup class in an ASP.NET application uses Dependency Injection extensively:
public class Startup
{
public Startup(IConfiguration configuration)
{
// ... code ...
}
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
// ... code ...
}
// ... code ...
}
In this example, the Startup() constructor requires a configuration parameter implementing the IConfiguration type. Since IConfiguration is one of the framework service types, the IoC Container knows how to create an instance of it and inject it into the Startup class applying the Constructor Injection approach. The same applies to the Configure() method. Keep in mind, however, that only the following framework service types can be injected in the Startup() constructor and in the Configure() method of a standard ASP.NET application: IWebHostEnvironment, IHostEnvironment, and IConfiguration. This is a special case for framework services because you don’t need to register them.
Registering framework services
In general, you have to register services needed by your ASP.NET application in the ConfigureServices() method of the Startup class. This method has an IServiceCollection parameter representing the list of services your application depends on. Practically, the collection represented by this parameter allows you to register a service in the IoC Container. Consider the following example:
public class Startup
{
// ... code ...
public void ConfigureServices(IServiceCollection services)
{
services.AddAuthentication(options =>
{
options.DefaultAuthenticateScheme = JwtBearerDefaults.AuthenticationScheme;
options.DefaultChallengeScheme = JwtBearerDefaults.AuthenticationScheme;
});
}
// ... code ...
}
Here, you are registering a dependency for managing authentication for your application. In this specific case, you are using the extension methodAddAuthentication() with the parameters describing the authentication type you want to use. The framework provides extension methods to register and configure dependencies for the most common services. It also provides the Add() method to register generic dependencies, as in the following example:
public class Startup
{
// ... code ...
public void ConfigureServices(IServiceCollection services)
{
services.Add(new ServiceDescriptor(typeof(ILog), new MyLogger()));
}
// ... code ...
}
In this case, you are registering a log service implementing the ILog interface. The second parameter of the Add() method is an instance of the MyLogger class you have implemented in your project. As you may guess, this registration creates a singleton service, i.e., a single instance of the MyLogger class that will fulfill any requests coming from your application.
Service lifetimes
This single instance of your dependency will live for the entire lifetime of your application. This may be suitable for a service like a logger, but it is unacceptable for other services. The IoC Container allows you to control the lifetime of a registered service. When you register a service specifying a lifetime, the container will automatically dispose of it accordingly. You have three service lifetimes:
Singleton: this lifetime creates one instance of the service. The service instance may be created at the registration time by using the Add() method, as you saw in the example above. Alternatively, the service instance can be created the first time it is requested by using the AddSingleton() method.
Transient: by using this lifetime, your service will be created each time it will be requested. This means, for example, that a service injected in the constructor of a class will last as long as that class instance exists. To create a service with the transient lifetime, you have to use the AddTransient() method.
Scoped: the scoped lifetime allows you to create an instance of a service for each client request. This is particularly useful in the ASP.NET context since it allows you to share the same service instance for the duration of an HTTP request processing. To enable the scoped lifetime, you need to use the AddScoped() method.
Choosing the right lifetime for the service you want to use is crucial both for the correct behavior of your application and for better resource management.
Managing Application Services
Most of the concepts you learned from framework services are still valid for your application services. However, framework services are already designed to be injectable. The classes you define in your application need to be adapted to leverage Dependency Injection and integrate with the IoC Container.
To see how to apply the Dependency Injection technique, recall the order management example shown early in this article and assume that those classes are within an ASP.NET application. You can download the code of that application from this GitHub repository by typing the following command in a terminal window:
This command will clone in your machine just the branch starting-point of the repository. After cloning the repository, you will find the dependency-injection-dotnet-core folder on your machine. In this folder, you have the OrderManagementWeb subfolder containing the ASP.NET Core project with the classes shown at the beginning of this article. In this section, you are going to modify this project to take advantage of the Dependency Injection and the built-in IoC Container.
Defining the abstractions
As the Dependency Inversion Principle suggests, modules should depend on abstractions. So, to define those abstractions, you can rely on interfaces.
Add a subfolder to the OrderManagementWeb folder and call it Interfaces. In the Interfaces folder, add the IOrderSender.cs file with the following content:
// OrderManagementWeb/Interfaces/IOrderSender.cs
using System.Threading.Tasks;
using OrderManagement.Models;
namespace OrderManagement.Interfaces
{
public interface IOrderSender
{
Task<string> Send(Order order);
}
}
This code defines the IOrderSender interface with just one method, Send(). Also, in the same folder, add the IOrderManager.cs file with the following interface definition:
// OrderManagementWeb/Interfaces/IOrderManager.cs
using System.Threading.Tasks;
using OrderManagement.Models;
namespace OrderManagement.Interfaces
{
public interface IOrderManager
{
public Task<string> Transmit(Order order);
}
}
The above code defines the IOrderManager interface with the Transmit() method.
Depending on the abstractions
Once defined the abstractions, you have to make your classes depending on them instead of the concrete class instances. As a first step, you need to redefine the OrderSender class so that it implements the IOrderSender interface. You also rename the class into HttpOrderSender to point out that this implementation sends the order via HTTP. So, open the OrderSender.cs file in the Managers folder and replace its content with the following:
// OrderManagementWeb/Managers/OrderSender.cs
using System.Net.Http;
using System.Text;
using System.Text.Json;
using System.Threading.Tasks;
using OrderManagement.Interfaces;
using OrderManagement.Models;
namespace OrderManagement
{
public class HttpOrderSender : IOrderSender
{
private static readonly HttpClient httpClient = new HttpClient();
public async Task<string> Send(Order order)
{
var jsonOrder = JsonSerializer.Serialize<Order>(order);
var stringContent = new StringContent(jsonOrder, UnicodeEncoding.UTF8, "application/json");
//This statement calls a not existing URL. This is just an example...
var response = await httpClient.PostAsync("https://mymicroservice.lan/myendpoint", stringContent);
return response.Content.ReadAsStringAsync().Result;
}
}
}
Now, you need to redefine also the OrderManager class so that it implements the IOrderManager interface. Open the OrderManager.cs file in the Managers folder and replace its content with the following:
// OrderManagementWeb/Managers/OrderManager.cs
using System.Threading.Tasks;
using OrderManagement.Interfaces;
using OrderManagement.Models;
namespace OrderManagement
{
public class OrderManager : IOrderManager
{
private IOrderSender orderSender;
public OrderManager(IOrderSender sender)
{
orderSender = sender;
}
public async Task<string> Transmit(Order order)
{
return await orderSender.Send(order);
}
}
}
You may notice that, differently from the previous version of the class, the Transmit() method no longer creates an instance of the OrderSender class. The dependency is now accessed via the class constructor.
With these changes, you broke the dependency between the OrderManager and the HttpOrderSender classes. Now, the OrderManager depends on the IOrderSender interface, i.e., its abstraction.
Registering the dependencies
Now you need to tell the IoC Container how to manage the dependencies based on the abstraction you have defined. In other words, you need to register the dependencies. As said, this registration happens in the Startup class of the project. So, open the Startup.cs file and replace the ConfigureServices() method with the following:
// OrderManagementWeb/Startup.cs
public class Startup
{
// ...code ...
public void ConfigureServices(IServiceCollection services)
{
services.AddControllers();
services.AddScoped<Interfaces.IOrderSender, HttpOrderSender>();
services.AddScoped<Interfaces.IOrderManager, OrderManager>();
}
// ...code ...
}
As you can see, you registered the dependencies by using the generic version of the AddScoped() method. Here you are asking the IoC Container to create an instance of the HttpOrderSender class whenever a request for the IOrderSender type is detected. Similarly, it should create an instance of the OrderManager class when theIOrderManager type is requested.
Note that even the AddController() method is an extension method provided by Microsoft.Extensions.DependencyInjection library that registers services for the Web API controllers.
Injecting the dependencies
Now it’s time to actually use all these dependencies. So, open the OrderController.cs file in the Controllers folder and replace its content with the following code:
// OrderManagementWeb/Controllers/OrderController.cs
using Microsoft.AspNetCore.Mvc;
using OrderManagement.Interfaces;
using OrderManagement.Models;
namespace OrderManagement.Controllers
{
[Route("api/[controller]")]
[ApiController]
public class OrderController : ControllerBase
{
private IOrderManager orderManager;
public OrderController(IOrderManager orderMngr)
{
orderManager = orderMngr;
}
[HttpPost]
public ActionResult<string> Post(Order order)
{
return Ok(orderManager.Transmit(order));
}
}
}
The new version of the Web API controller defines a private orderManager variable. Its value represents the instance of a service implementing the IOrderManager interface. The value of this variable is assigned in the constructor, which has an IOrderManager type parameter. With this parameter, the constructor is requesting the IoC Container a service instance of that type. The IoC Container searches in its service collection a registration that can satisfy this request and passes such an instance to the controller. But that’s not all. The IoC Controller also looks for other indirect dependencies and resolve them. This means that while creating the instance of the OrderManager class, the IoC Container also resolves its internal dependency on the IOrderSender abstraction. So you don’t have to worry about indirect dependencies: they are all resolved under the hood simply because the Web API controller declared to need a registered service.
As you noticed in these examples, the Constructor Injection is the default approach used by the IoC Container to inject dependencies in a class. If you want to use the Method Injection approach, you should request it explicitly by using the FromServices attribute. This example shows how you could use this attribute:
[HttpPost]
public ActionResult<string> Post([FromServices]IOrderManager orderManager)
{
return Ok(orderManager.Transmit(order));
}
The third injection approach, the Property Injection, is not supported by the built-in IoC Container.
Dependency Injection in a Console Application
In the previous section, you implemented Dependency Injection for an ASP.NET Web application. You followed a few steps to register and get your dependencies automatically resolved by the built-in IoC Container. However, you may still feel something magic in the way it happens since the ASP.NET Core infrastructure provides you with some implicit behaviors. However, the Dependency Injection mechanism provided by the IoC Container is not just for Web applications. You can use it in any type of application.
In this section, you will learn how to leverage the IoC infrastructure in a console application, and some behaviors that may still look obscure will be hopefully clarified. So, move in the dependency-injection-dotnet-core folder you created when cloned the ASP.NET application and run the following command in a terminal window:
dotnet new console -o OrderManagementConsole
This command creates an OrderManagementConsole folder with a basic console application project. Now, copy in the OrderManagementConsole folder the Interfaces, Managers, and Models folders from the ASP.NET project you modified in the previous section. Basically, you are reusing the same classes related to the order management process you defined in the ASP.NET project.
After this preparation, the first step to enable your console application to take advantage of the IoC Container is to add the Microsoft.Extensions.DependencyInjection package to your project with the following command:
Then, you have to write some code to set up the IoC Container in your console application. Open the Program.cs file and replace its content with the following:
// OrderManagementConsole/Program.cs
using System;
using Microsoft.Extensions.DependencyInjection;
using OrderManagement;
using OrderManagement.Interfaces;
using OrderManagement.Models;
namespace OrderManagementConsole
{
class Program
{
private static IServiceProvider serviceProvider;
static void Main(string[] args)
{
ConfigureServices();
var orderManager = serviceProvider.GetService<IOrderManager>();
var order = CreateOrder();
orderManager.Transmit(order);
}
private static void ConfigureServices()
{
var services = new ServiceCollection();
services.AddTransient<IOrderSender, HttpOrderSender>();
services.AddTransient<IOrderManager, OrderManager>();
serviceProvider = services.BuildServiceProvider();
}
private static Order CreateOrder()
{
return new Order {
CustomerId = "12345",
Date = new DateTime(),
TotalAmount = 145,
Items = new System.Collections.Generic.List<OrderItem>
{
new OrderItem {
ItemId = "99999",
Quantity = 1,
Price = 145
}
}
};
}
}
}
You see that the first operation in the Main() method of the Program class is configuring the services. Taking a look at the ConfigureServices() method, you see that this time you have to create the services collection explicitly. Then, you register your services with the transient lifetime: the dependencies should live just the time needed to manage the order. Finally, you get the service provider by using the BuildServiceProvider() method of the services collection and assign it to the serviceProvider private variable.
You use this service provider to get an instance of a registered service. For example, in the Main() method, you get an instance of the IOrderManager service type by using the GetService<IOrderManager>() method. From now on, you can use this instance to manage an order. Of course, as in the ASP.NET case, the orderManager instance has any indirect dependency resolved.
Finally, the CreateOrder() method just creates a dummy order to be passed to the Transmit() method of the order manager.
Summary
This article tried to clarify some concepts related to the Dependency Injection design pattern and focused on the infrastructure provided by .NET Core to support it. After introducing a few general definitions, you learned how to configure an ASP.NET Core application to use the built-in IoC container and register framework services. Then, you adapted the classes of an ASP.NET application to apply the Dependency Inversion Principle and discovered how to register your dependency in the IoC Container specifying the desired lifetime. Finally, you saw how to use the IoC Container even in a console application.
Here you will get detailed information about joins in SQL.
Join is a very basic concept in SQL which can be confusing at times. The joins are used when we need to find out the solution to a query involving the attributes of more than one table which have at least one attribute in common. Hence the need of join is pretty much clear in itself. There are different types of join which are used for different purposes.
Joins in SQL
Let’s say we have two tables, a table named STUDENT and the other table named TEACHER.
The first table “STUDENT” stores the reference details of the student and the second table “TEACHER” stores the details of the teachers who are in the school and the class they are teaching.
STUDENT
ClassID
Name
House address
101
John
xyz
201
David
byc
301
Victor
abc
401
Patrick
def
TEACHER
Teacher id
Class name
ClassID
1
First
101
2
Second
201
3
Third
301
4
Fourth
401
In the second table, the “ClassID” is a foreign key which is used as a reference of the first table in the second one.
Now, if we want to find out the name of the student whose teacher id is 1; we need to find the join of the above mentioned tables since it requires us to gather the information of both the tables. Hence, the joins are only used where both the tables have at least one attribute (here ClassID) in common and we need to find the solution to a query which involves the attributes from both the tables.
Types of Join
Basically there are four types of joins namely, inner join, left join, right join, full outer join. The explanation of each one of the mentioned joins is as given below.
1. Inner Join
Let us consider the following two tables, the first table’s name is Country (saves the id of different countries) and the other table’s name is State (saves the various states in those countries).
COUNTRY
CountryId
CountryName
1
China
2
PH
3
USA
STATE
StateId
CountryId
StateName
01
2
PASAY
02
2
MAKATI
03
5
NAVOTAS
04
6
PATEROS
select * from COUNTRY
inner join STATE
on COUNTRY.CountryId=STATE.CountryId
The above mentioned command applies an inner join on the two table, since the common attribute is Country id, we have applied the join on the same.
The inner join returns all the matching values from both the tables. Here, in table State, since the only matching CountryId value in the country table is {CountryId = 2}, as a result of the inner join we will get the following result:
CountryId
CountryName
StateId
StateName
2
PH
01
PASAY
2
PH
02
MAKATI
2. Right Join
The right (or right outer join) on the other hand, displays the data which is common in both the tables, as well as the data which is present in the right table (exclusively).
This basically means that the entire right table’s data would be displayed on application of a right join.
When there is no match in the Left Table, it displays NULL.
Example:
COUNTRY
CountryId
CountryName
1
China
2
PH
3
USA
STATE
StateId
CountryId
StateName
01
2
PASAY
02
2
MAKATI
03
5
NAVOTAS
04
6
PATEROS
select * from COUNTRY
right join STATE
on COUNTRY.CountryId=STATE.CountryId
The above mentioned command applies a right join on the two tables, since the common attribute is CountryId; we have applied the join on CountryId itself.
The right table is the second table we refer to.
We would get the following table as a result of the application of the right join:
CountryId
CountryName
StateId
StateName
2
PH
01
PASAY
2
PH
02
MAKATI
5
NULL
03
NAVOTAS
6
NULL
04
PATEROS
In the result, it is clearly depicted that the values in the Left Table which have absolutely no matching values in the Right one are not being displayed. Only those values of the Left Table are displayed which have common attributes with the Right one. Whereas all the values in the Right Table are displayed. The rows in the Right Table with no match in the Left Table are displayed as NULL (Empty).
3. Left Join
The left join (or left outer join) on the other hand, displays the data which is common in both the tables, as well as the data which is present in the left table (exclusively).
This basically means that the entire Left Table’s data would be displayed on application of a Left Join.
When there is no match in the Left Table, it displays NULL.
COUNTRY
CountryId
CountryName
1
China
2
PH
3
USA
STATE
StateId
CountryId
StateName
01
2
PASAY
02
2
MAKATI
03
5
NAVOTAS
04
6
PATEROS
select * from COUNTRY
left join STATE
on COUNTRY.CountryId =STATE.CountryId
The above mentioned command applies a Left Join on the two tables, since the common attribute is CountryId; we have applied the join on Countryid itself.
The Left Table is the first table we refer to.
We would get the following table as a result on application of left join:
CountryId
CountryName
Stateid
Statename
1
China
NULL
NULL
2
PH
01
PASAY
2
PH
02
MAKATI
3
USA
NULL
NULL
In the result, it is clearly depicted that the values in the right column which have absolutely no matching values in the left one are not being displayed. Only those attributes of the right column are displayed which have common attributes with the left one. Whereas all the values in the Left Table are displayed. The rows in the Left Table with no match in the Right Table are displayed as NULL (Empty)
4. Full Outer Join
The Full Outer Join, as the name suggests, shows all the content of both the tables. The Full Outer Join returns all matching records from both the tables whether the other table matches or not.
COUNTRY
CountryId
CountryName
1
China
2
PH
3
USA
STATE
StateId
CountryId
StateName
01
2
PASAY
02
2
MAKATI
03
5
NAVOTAS
04
6
QUEZON
select * from COUNTRY
full outer join STATE
on COUNTRY.CountryId=TEACHER.CountryId
The above mentioned command applies a Full Outer Join on the two tables, since the common attribute is CountryId; we have applied the join on Countryid itself.
We would get the following table as a result on application of Full Outer Join:
CountryId
CountryName
Stateid
Statename
1
China
NULL
NULL
2
PH
01
PASAY
2
PH
02
MAKATI
3
USA
NULL
NULL
NULL
NULL
03
NAVOTAS
NULL
NULL
04
PATEROS
This Join results in all the rows. We get NULL (Empty), when there is no match.
Joins are essentially important to work with tables in SQL and the above mentioned description genuinely elaborate the usage of each one of them.
Images are critical. Whether it is marketing banners, product images or logos, it is impossible to imagine a website without images. Sadly though, images are often heavy files making them the single biggest contributor to the page bloat. According the HTTP Archive’s State of Images report, the median page size on desktops is 1511 KB and images account for nearly 45% (650 KB) of that total.
That said, it’s not like we can simply do away with images. They’re too important to the overall user experience. Instead, we need to make our web pages load really fast with them. In this guide, we will cover all of the ins and outs of lazy loading images, a technique that helps improve the time it takes for a web page to load by deferring image loads until they are needed.
Before we dive right in, here is a sample video that demonstrates the concept. In short, a gray placeholder box is rendered on the page until it scrolls into view—at which point the actual image loads in place of the box.
Chapter 1: What is Lazy Loading?
We often associate the word “lazy” with avoiding work as long as possible, or the sheer act of wanting to do nothing at all.
Similarly, lazy loading defers the loading of resources on the page as long as they are not needed. Instead of loading them right away, which is what normally happens, we allow them to load later.
Lazy Loading is a set of techniques in web and application development that defers the loading of resources on a page to a later point in time—when those resources are actually needed instead of loading them up front. These techniques help in improving performance, better utilization of the device’s resources and reducing associated costs.
The technique of lazy loading can be applied to just about any resources on a page. For example, even a JavaScript file can be held back if it is best not to load it initially. Same deal for an image—load it when we need it.
We will stick to lazy loading images in this guide, but it’s good to know it can be applied to other assets.
Chapter 2: Why Lazy Load at All?
If the user never scrolls to the point of the page that contains the image, then the user will never see that image. It also never loads in the first place because, hey, it was never needed.
You may already start to see how this benefits both you and the user. Here are two of the advantages we get with lazy loading.
Performance Gains
The obvious benefit is that we get smaller web pages that load faster. Lazy loading reduces the number of images that need to be loaded on a page up front. Fewer image requests mean fewer bytes to download. And fewer bytes to download means the page renders faster than if those bytes and requests were being made.
This ensures that any device on any network is able to download and process the remaining resources much faster. Hence, the time from request to render becomes smaller and the page becomes usable much earlier. Win-win!
Cost reduction
The second benefit is for you as a website administrator. Cloud hosting services, like Content Delivery Networks (CDNs) or web servers or storages, deliver images (or any asset for that matter) at a cost based on the number of bytes transferred. A lazy loaded image may never get loaded if the user never reaches it. Thus, you may reduce the total bytes delivered on the page and ultimately save yourself a few pennies in the process. This is especially true for users that instantly bounce off a page or interact only with the top portion of the content.
The reduction in bytes transferred from your delivery network or server reduces delivery costs. This will become more apparent as we explore lazy loading in the coming sections.
Just how much will you save? You can find out which images are a candidate for lazy loading and how many bytes you can save on the initial page load by using the Google Lighthouse audit tool. This has a section dedicated for offscreen images. You can also use ImageKit’s website analyzer to identify if your website uses lazy loading or not apart from other critical image related optimizations on your page.
Lazy loading is critical not only to good performance but also to deliver a good user experience. Since combining performance and user experience with lazy loading is important and challenging, we will continue to address this topic in more detail throughout this guide after we have looked at different ways to lazy load images.
Chapter 3: Lazy Loading Techniques for Images
There are two common ways that we load images to a page: the <img> tag and the CSS background-image property. We will first look at the more common of the two, the <img> tag and then move to CSS background images.
Lazy loading images in an image tag
Let’s start with the typical HTML markup for an image:
HTML:
<img src="/path/to/some/image.jpg" />
The markup for lazy loading images is pretty similar.
Step one is to prevent the image load up front. The browser uses the src attribute of the tag to trigger the image load. It doesn’t matter if it is the first or the 1,000th image in your HTML. If the browser gets the src attribute, it will trigger the image to be downloaded, regardless of whether it is in or out of current view.
To defer the load, put the image URL in an attribute other than src. Let’s say we specify the image URL in the data-src attribute of the image tag. Now that src is empty and the browser won’t trigger the image load:
Now that we’re preventing the image from loading, we need to tell the browser when to load it. Otherwise, it will never happen. For this, we check that as soon as the image (i.e. its placeholder) enters the viewport, we trigger the load.
There are two ways to check when an image enters the viewport. Let’s look at both of them with working code samples.
Method 1: Trigger the image load using Javascript events
This technique uses event listeners on the scroll, resize and orientationChange events in the browser. The scroll event is pretty clear cut because it watches where the user is on a page as scrolling occurs. The resize and orientationChange events are equally important. The resize event occurs when the browser window size changes, whereas orientationChange gets triggered when the device is rotated from landscape to portrait, or vice versa.
We can use these three events to recognize a change in the screen and determine the number of images that become visible on the screen and trigger them to load accordingly.
When any of these events occur, we find all the images on the page that are deferred and, from these images, we check which ones are currently in the viewport. This is done using an image’s top offset, the current document top position, and window height. If an image has entered the viewport, we pick the URL from the data-src attribute and move it to the src attribute and the image will load as a result.
Note that we will ask JavaScript to select images that contain a lazy class. Once the image has loaded, we’ll remove the class because it no longer needs to trigger an event. And, once all the images are loaded, we remove the event listeners as well.
When we scroll, the scroll event triggers multiple times rapidly. Thus, for performance, we are adding a small timeout to our script that throttles the lazy loading function execution so it doesn’t block other tasks running in the same thread in the browser.
Note that the first three images in this example are loaded up front. The URL is present directly in the src attribute instead of the data-src attribute. This is essential for a good user experience. Since these images are at the top of the page, they should be made visible as soon as possible. There’s no need to wait for JavaScript to load them.
Method 2: Trigger the image load using the Intersection Observer API
The Intersection Observer API is relatively new. It makes it simple to detect when an element enters the viewport and take an action when it does. In the previous method, we had to bind events, keep performance in mind and implement a way to calculate if the element was in the viewport or not. The Intersection Observer API removes all that overhead by avoiding the math and delivering great performance out of the box.
Below is an example using the API to lazy load images. We attach the observer on all the images to be lazy loaded. Once the API detects that the element has entered the viewport, using the isIntersecting property, we pick the URL from the data-src attribute and move it to the src attribute for the browser to trigger the image load. Once this is done, we remove the lazy class from the image and also remove the observer from that image.
If you compare the image loading times for the two methods (event listeners vs. Intersection Observer), you will find that images load much faster using the Intersection Observer API and that the action is triggered quicker as well— and yet the site doesn’t appear sluggish at all, even in the process of scrolling. In the method involving event listeners, we had to add a timeout to make it performant, which has a slightly negative impact on the user experience as the image load is triggered with a slight delay.
However, like any new feature, the support for Intersection Observer API is not available across all browsers.
This browser support data is from Caniuse, which has more detail. A number indicates that browser supports the feature at that version and up.
Desktop
Chrome
Opera
Firefox
IE
Edge
Safari
58
45
55
No
16
12.1
Mobile / Tablet
iOS Safari
Opera Mobile
Opera Mini
Android
Android Chrome
Android Firefox
12.2-12.4
46
No
76
78
68
So, we need to fall back to the event listener method in browsers where the Intersection Observer API is not supported. We have taken this into account in the example above.
CSS:
.my-class {
background-image: url('/path/to/some/image.jpg');
/* more styles */
}
CSS background images are not as straightforward as the image tag. To load them, the browser needs to build the DOM tree as well as the CSSOM tree to decide if the CSS style applies to a DOM node in the current document. If the CSS rule specifying the background image does not apply to an element in the document, then the browser does not load the background image. If the CSS rule is applicable to an element in the current document, then the browser loads the image.
Huh? This may seem complex at first, but this same behavior forms the basis of the technique for lazy loading background images. Simply put, we trick the browser into not applying the background-image CSS property to an element, till that element comes into the viewport.
Here is a working example that lazy loads a CSS background image.
One thing to note here is that the JavaScript code for lazy loading is still the same. We are still using the Intersection Observer API method with a fallback to the event listeners. The “trick” lies in the CSS.
We have an element with ID bg-image that has a background-image. However, when we add the lazy class to the element, we can override the background-image property by setting the value of it to none in the CSS.
Since an element with an ID and a class has higher specificity in CSS than an ID alone, the browser applies the property background-image: none to the element initially. When we scroll down, the Intersection Observer API (or event listeners, depending on which method you choose) detects that the image is in the viewport, it removes the lazy class from the element. This changes the applicable CSS and applies the actual background-image property to the element, triggering the load of the background image.
Chapter 5: Creating a Better User Experience With Lazy Loading
Lazy loading presents a great performance benefit. For an e-commerce company that loads hundreds of product images on a page, lazy loading can provide a significant improvement in initial page loads while decreasing bandwidth consumption.
However, a lot of companies do not opt for lazy loading because they believe it goes against delivering a great user experience (i.e. the initial placeholder is ugly, the load times are slow etc.).
In this section, we will try to solve some concerns around user experience with lazy loading of images.
Tip 1. Use the Right Placeholder
A placeholder is what appears in the container until the actual image is loaded. Normally, we see developers using a solid color placeholder for images or a single image as a placeholder for all images.
The examples we’ve looked at so far have used a similar approach: a box with a solid light gray background. However, we can do better to provide a more pleasing user experience. Below are some two examples of using better placeholders for our images.
Dominant Color Placeholder
Instead of using a fixed color for the image placeholder, we find the dominant color from the original image and use that as a placeholder. This technique has been used for quite some time by Google in its image search results as well as by Pinterest in its grid design.
Pinterest uses the dominant color of the image as the background color for image placeholders. (Source)
This might look complex to achieve, but Manuel Wieser has an elegant solution to accomplishing this by scaling down the image to down to a 1×1 pixel and then scale it up to the size of the placeholder—a very rough approximation but a simple, no-fuss way to get a single dominant color. Using ImageKit, the dominant color placeholder can be obtained using a chained transform in ImageKit as shown below.
<!-- Original image at 400x300 -->
<img src="https://ik.imagekit.io/demo/img/image4.jpeg?tr=w-400,h-300" alt="original image" />
<!-- Dominant color image with same dimensions -->
<img src="https://ik.imagekit.io/demo/img/image4.jpeg?tr=w-1,h-1:w-400,h-300" alt="dominant color placeholder" />
The placeholder image is just 661 bytes in size compared to the original image that is 12700 bytes—19x smaller. And it provides a nicer transition experience from placeholder to the actual image.
Here is a video demonstrating how this effect works for the user.
We can extend the above idea of using a dominant color placeholder further. Instead of using a single color, we use a very low-quality, blurred version of the original image as the placeholder. Not only does it look good, but it also gives the user some idea about what the actual image looks like and the perception that the image load is in progress. This is great for improving the perceived loading experience. This technique has been utilized by the likes of Facebook and Medium.
LQIP image URL example using ImageKit:
<!-- Original image at 400x300 -->
<img src="https://ik.imagekit.io/demo/img/image4.jpeg?tr=w-400,h-300" alt="original image" />
<!-- Low quality image placeholder with same dimensions -->
<img src="https://ik.imagekit.io/demo/img/image4.jpeg?tr=w-400,h-300,bl-30,q-50" alt="dominant color placeholder" />
The LQIP is 1300 bytes in size, still almost 10x smaller than the original image and a significant improvement in terms of visual experience over any other placeholder technique.
Here is a video demonstrating how this effect works for the user.
It is clear that using either dominant color or LQIP placeholders provides a smoother transition from the placeholder to the actual image, gives the user an idea of what is to come in place of that placeholder, and improves loading perception.
Tip 2: Add Buffer Time for Images to Load
When we discussed different methods to trigger image loads, we checked for the point of time where the image enters the viewport, i.e. the image load is triggered when the top edge of the image placeholder coincides with the bottom edge of the viewport.
The problem with this is that users might scroll really fast through the page and the image will need some time to load and appear on the screen. Combined with throttling possibly further delaying the load, the user may wind up waiting a few milliseconds longer for the image to show up. Not great for user experience!
While we can get a pretty good user experience using the Intersection Observer API for performance and LQIP for smoother transitions, there is another simple trick that you can use to ensure that the images are always loaded completely when they enter the viewport : introduce a margin to the trigger point for images.
Instead of loading the image exactly when it enters the viewport, load it when it’s, let’s say, 500px before it enters the viewport. This provides additional time, between the load trigger and the actual entry in the viewport, for the images to load.
With the Intersection Observer API, you can use the root parameter along with the rootMargin parameter (works as standard CSS margin rule), to increase the effective bounding box that is considered to find the intersection. With the event listener method, instead of checking for the difference between the image edge and the viewport edge to be 0, we can use a positive number to add some threshold.
If you watch the following screencast closely, you’ll notice that the fifth image in the sequence is loaded when the third image is in view. Similarly, the sixth image is loaded when the fourth is in view, and so on. This way, we are giving sufficient time for the images to load completely and, in most cases, the user won’t see the placeholder at all.
If you didn’t notice earlier, in all our examples, the third image (image3.jpg) is always loaded up front, even though it is outside the viewport. This was also done following the same principal: load slightly in advance instead of loading exactly at the threshold for better user experience.
Tip 3: Avoid Content Reflow
This is another trivial point, which if solved, can help maintain a good user experience.
When there is no image, the browser doesn’t know the size it will take up. And if we do not specify it using CSS, then the enclosing container would have no dimensions, i.e. it will be read as 0x0 pixels.
When the image loads, the browser will drop it into the screen and reflow the content to fit it. This sudden change in the layout causes other elements to move around and it is called content reflow, or shifting. Michael Scharnagl goes into great depth explaining how this creates an unpleasant user experience.
This can be avoided by specifying a height and/or width for the enclosing container so that the browser can paint the image container with a known height and width. Later, when the image loads, since the container size is already specified and the image fits into that perfectly, the rest of the content around that container does not move.
Tip 4: Avoid Lazy Loading Every Image
This is a mistake that developers often make because it’s super tempting to think that deferring image loads is good all the time. But, like life itself, it is possible to have too much of a good thing. Lazy loading might reduce the initial page load, but it also might result in a bad user experience if some images are deferred when they should not be.
We can follow some general principles to identify which images should be lazy loaded. For example, any image that is present in the viewport, or at the beginning of the webpage, should probably not be lazy loaded. This applies to any header image, marketing banner, logos, or really anything that the user would see when initially landing on a page. Also, remember that mobile and desktop devices will have different screen sizes and hence a different number of images that will be visible on the screen initially. You’ll want to take the device that’s being used into account and decide which resources to load up front and which to lazy load.
Another example is any image that is even slightly off the viewport in the initial load should not probably not be lazy loaded. This is going by the principle discussed above—load slightly in advance. So, let’s say any image that is 500px or a single scroll from the bottom of the viewport can be loaded up front as well.
One more example is if the page is short. It may be just a single scroll or a couple of scrolls, or perhaps there are less than five images outside the viewport. In these cases, you can probably leave lazy loading out altogether. It would not provide any significant benefit to the end user in terms of performance and the additional JavaScript that you load on the page to enable lazy loading will offset any potential gain you get from it.
Chapter 5: Lazy Loading’s Dependency on JavaScript
The entire idea of lazy loading is dependent on JavaScript being enabled and available in the user’s browser. While most of your users will likely have JavaScript enabled, it is essential to plan for cases where it is not.
You could either show a message telling users why the images won’t load and encourage them to either use a modern browser or enable JavaScript.
Another route is to use the noscript tag. However, this approach comes with some gotchas. This question thread on Stack Overflow does a great job addressing these concerns and is a recommended read for anyone looking to address this set of users.
Chapter 6: Popular JavaScript Libraries for Lazy Loading
Since environments and implementation details can vary across browsers and devices, you might want to consider a tried and tested library for lazy loading rather than spinning something up from scratch.
Here is a list of popular libraries and platform specific plugins that will allow you to implement lazy loading with minimal effort:
Yet Another Lazy Loader: This library uses the Intersection Observer API and falls back to event-based lazy loading for browsers that do not yet support it. This is great for just about any HTML element but unfortunately does not work on background images in CSS. The good news is that it supports IE back to version 11.
lazysizes: This is a very popular library with extensive functionality. It includes support for responsive image srcset and sizes attributes and provides superb performance even though it does not make use of the Intersection Observer API.
WordPress A3 Lazy Load: There are plenty of lazy loading WordPress plugins out there, but this one comes with a robust set of features, including a fallback when JavaScript is unavailable.
jQuery Lazy: A simple library that uses a jQuery implementation.
Once you have implemented lazy loading, you will likely want to check that it’s working as intended. The simplest way would be to open up the developer tools in your browser.
From there, go to Network > Images. When you refresh the page for the first time, you should only see loaded images in the list.
Then, as you start scrolling down the page, other image load requests would get triggered and loaded. You can also notice the timings for image load in the waterfall column in this view. It would help you identify image loading issues if any or issues in triggering the image load.
Another way would be to run the Google Chrome Lighthouse audit report on your page after you have implemented the changes and look for suggestions under the “Offscreen images” section.
Conclusion
We have covered a lot of ground about lazy loading images! Lazy loading—if implemented well—can have significant benefits on your site’s performance the loading performance while reducing the overall page size and delivery costs, thanks to deferring unnecessary resources up front.
So, what are you waiting for? Get started with lazy loading images now! And, if you need a little reminder of how this works, save a copy of the following infographic.
Notepad is among the most popular applications, and that is why Microsoft has included it in every version of Windows. It has a long history, and it has maintained a simple and clean interface. The simplicity of this text editor I use, and that is why most people have developed a preference over it. But wait? The developers keep on making improvements to suit your needs.
There is another text editor outside notepad, which is notepad ++. It has a bunch of features that allow you to complete more complex tasks. It has syntax folding, syntax highlighting when writing code and multi editing. Once you are in a good position to use notepad++ you will need WinRAR to help you compress storage required to store data by removing unnecessary data to pave the way for what you want to save. You can simply get it at rocketfiles.com.
Therefore with such an amazing text editor, you will not miss having its alternatives, and that is why in this article I will focus on its alternatives.
7 Best Notepad++ Alternatives
1. Brackets
his is a typical Text editor that offers unique tools for front end web developers and designers. It offers the following features:-
Features
It has support for an extension
It offers a live preview, which implies you can edit the code using the editors and as well preview it in the browser within the editor.
It is among the popular text editor across all the platforms since it is capable of supporting various programming languages. It is highly responsive such that it automatically resizes tab size when you open multiple tabs.
Features
It offers complete keyboard support
It is an open-source
It is not mandatory to purchase the license
No costs during installation
Pros
It has auto-indentation feature
It is easy to install and use
It has intelligence sense features
Cons
It lacks git plugins.
3. Atom
It is a free open source editor with lots of features. It is compatible with Linux, Windows, and Mac OS.
Features
It can autocomplete texts
It automatically identifies codes
It provides syntax highlighting
Pros
It is easy to install
Free, open-source editor
It offers several plugins to enhance its reflectiveness
It has an elegant interface
Cons
It is a bit slower when you compare to the other editors
It is large in size
4. Visual Studio Code
This is also another popular text editor that can support multiple programming languages. It is compatible with various operating systems, and it offers competent community support.
Features
It has an inbuilt feature which is done signed for file comparison
It is an open-source editor
It offers an inbuilt Git support
It can be installed across multiple operating systems
It supports user commands
Pros
It is easily customizable
It is light in weight
5. Netbeans
This is yet another text editor that is majorly used for Java development. It is an Integrated Development Environment that is based on the concept of modularity.
Features
It can autocomplete various texts
It automatically detects the codes
It has syntax highlighting features
Pros
It offers easy debugging feature
It is an open-source text editor
It is based on the modular concept
It is an ant-based project system
It can support maven
Cons
It is heavy
It offers less skin customization
6. TextMate
This is a typical text editor, which is an alternative for notepad++, and it can be used for general purposes. Here are some of its dominant features:-
Features
It is customizable
It provides syntax highlighting
It autocompletes texts
It automatically identifies codes
Pros
It has a live preview feature
It can list function in the current document
Cons
It can only be installed in Mac OS.
7. TextPad
This text editor was initially developers to be used in Microsoft OS by Helios Software solution. To be able to use it, you will have to purchase it.
Features
Supports multiple programming languages
It is capable of maintaining block indent
You can scroll multiple files synchronically
It offers automatic code identification
It automatically integrates JDK
Conclusion
Notepad++, which is available and free at rocketfiles.com, is popular because of its unique features. There are also alternatives that I have listed in this article that can actively perform similar tasks. You can use any of these editors for programming or general purposes. The good thing about most of these text editors is that they are easy to install and use. Most of them are also free except text pad, which you have to purchase it before using it. Generally, most of these text editors can compliment notepad ++ perfectly.
A local database is very essential for developing small scale C# applications, because it doesn’t requires a server to store the data. So this article is on how to connect and use C# local database.Well I am pretty sure that most of you would thing, what is a Local Database? A local database is database which can be used locally on a computer, it doesn’t require a server. The advantage of using a local database is you can easily migrate your project from one computer to another (you don’t need to setup/configure a database server). Microsoft provides local database within visual studio which is often called as SQLCE (CE stands for compact edition).
So let’s get started!
1. First of all create a new project in C# (make sure you select the Netframe version above 3.5, because local database is supported in Netframe version 4.0 or above).
2. Now right click your project under solution explorer -> select add new item.
3. A new window will be popped up, search for local database and add it.
4. Again a new window will be popped up which ask up to choose a Database Model select Dataset and hit Next & hit Finish.
5. Now we have added a local database in our C# application.
6. Now we need to establish our connection between our local database & C# application.
7. So simply add a button from toolbox and change the text to Start Connection.
8. Double click your form and import the following:
using System.Data.SqlServerCe;
Note: If you are facing an error then watch the video tutorial.
9. Double click the button and add the following code:
SqlCeConnection Conn=new SqlCeConnection(//specify the connection string here)
10. In order to find the connection string, go to solution explorer and open app.config file.
11. In the above screenshot you can see the connection string just copy it and paste it here inside the brackets.
SqlCeConnection Conn=new SqlCeConnection(//specify the connection string here)
12. We are almost done now we just need to open the connection so just double click the button and add the following code:
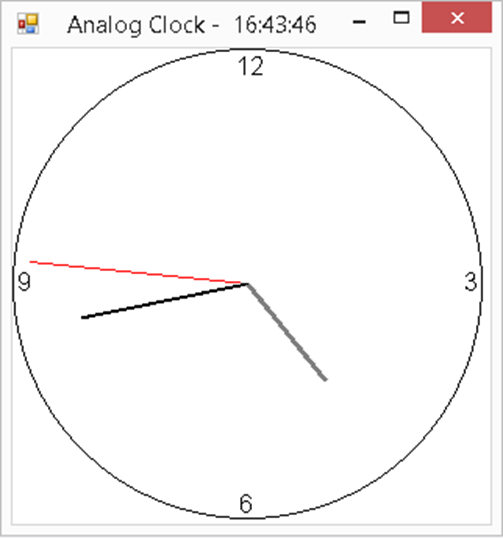
In this tutorial we are going to use a bit of graphics class to design a C# analog clock. We have also used a timer to continuously move our clock’s pointer.
Concept
We will first initialize some angle values to second, minute, hour hand.
Then draw the clock using the graphics class, save it as a bitmap variable and load it in the picturebox.
Finally Use the timer to move the second hand.
Instructions
Create a new windows form applicaton project in visual c#.
Add a picture box on the form.
Double click the form to switch to code view.
Delete all the existing code and paste the code given below.
C# Analog Clock Program
Code:
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
namespace AnalogClock
{
public partial class Form1 : Form
{
Timer t = new Timer();
int WIDTH = 300, HEIGHT = 300, secHAND = 140, minHAND = 110, hrHAND = 80;
//center
int cx, cy;
Bitmap bmp;
Graphics g;
public Form1()
{
InitializeComponent();
}
private void Form1_Load(object sender, EventArgs e)
{
//create bitmap
bmp = new Bitmap(WIDTH + 1, HEIGHT + 1);
//center
cx = WIDTH / 2;
cy = HEIGHT / 2;
//backcolor
this.BackColor = Color.White;
//timer
t.Interval = 1000; //in millisecond
t.Tick += new EventHandler(this.t_Tick);
t.Start();
}
private void t_Tick(object sender, EventArgs e)
{
//create graphics
g = Graphics.FromImage(bmp);
//get time
int ss = DateTime.Now.Second;
int mm = DateTime.Now.Minute;
int hh = DateTime.Now.Hour;
int[] handCoord = new int[2];
//clear
g.Clear(Color.White);
//draw circle
g.DrawEllipse(new Pen(Color.Black, 1f), 0, 0, WIDTH, HEIGHT);
//draw figure
g.DrawString("12", new Font("Arial", 12), Brushes.Black, new PointF(140, 2));
g.DrawString("3", new Font("Arial", 12), Brushes.Black, new PointF(286, 140));
g.DrawString("6", new Font("Arial", 12), Brushes.Black, new PointF(142, 282));
g.DrawString("9", new Font("Arial", 12), Brushes.Black, new PointF(0, 140));
//second hand
handCoord = msCoord(ss, secHAND);
g.DrawLine(new Pen(Color.Red, 1f), new Point(cx, cy), new Point(handCoord[0], handCoord[1]));
//minute hand
handCoord = msCoord(mm, minHAND);
g.DrawLine(new Pen(Color.Black, 2f), new Point(cx, cy), new Point(handCoord[0], handCoord[1]));
//hour hand
handCoord = hrCoord(hh % 12, mm, hrHAND);
g.DrawLine(new Pen(Color.Gray, 3f), new Point(cx, cy), new Point(handCoord[0], handCoord[1]));
//load bmp in picturebox1
pictureBox1.Image = bmp;
//disp time
this.Text = "Analog Clock - " + hh + ":" + mm + ":" + ss;
//dispose
g.Dispose();
}
//coord for minute and second hand
private int[] msCoord(int val, int hlen)
{
int[] coord = new int[2];
val *= 6; //each minute and second make 6 degree
if (val >= 0 && val <= 180)
{
coord[0] = cx + (int)(hlen * Math.Sin(Math.PI * val / 180));
coord[1] = cy - (int)(hlen * Math.Cos(Math.PI * val / 180));
}
else
{
coord[0] = cx - (int)(hlen * -Math.Sin(Math.PI * val / 180));
coord[1] = cy - (int)(hlen * Math.Cos(Math.PI * val / 180));
}
return coord;
}
//coord for hour hand
private int[] hrCoord(int hval, int mval, int hlen)
{
int[] coord = new int[2];
//each hour makes 30 degree
//each min makes 0.5 degree
int val = (int)((hval * 30) + (mval * 0.5));
if (val >= 0 && val <= 180)
{
coord[0] = cx + (int)(hlen * Math.Sin(Math.PI * val / 180));
coord[1] = cy - (int)(hlen * Math.Cos(Math.PI * val / 180));
}
else
{
coord[0] = cx - (int)(hlen * -Math.Sin(Math.PI * val / 180));
coord[1] = cy - (int)(hlen * Math.Cos(Math.PI * val / 180));
}
return coord;
}
}
}
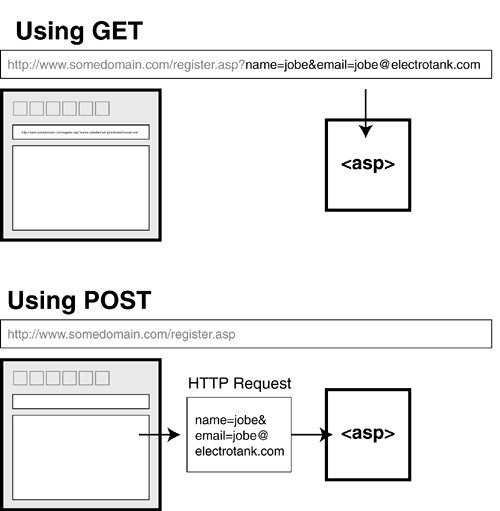
Http protocol supports the following methods to retrieve data such as get, post, put, delete etc. In this article, I will tell you about the difference between GET and POST methods.
These methods are basically used to get and send any data. Because of these methods, the request-response between server and client exist. To send data streams we use these two methods. GET and POST are the most common HTTP methods.
Difference between GET and POST Method
GET
POST
We add parameters in URL and get data in response.
Send additional data from the client or browser to the server.
Sends data as part of URI (uniform resource identifier)
Sends data as HTTP content.
get return same results every time.
The post method implements in that way it changes with every request.
We can send limited data in the header.
We can send a large amount of data because its part of the request body.
It is not much secure because data is exposed to URL and we can easily bookmark it and send it.
It is more secure because data is passed in the request body and user not able to bookmark it
You can cache the data.
You cannot cache post request data.
GET is bounded by the max. URL length continued by the browser and web server.
POST doesn’t have such conditions.
GET is used to request data from a particular resource.
POST is used to send info to a server to create/update a resource.
parameters passed in URL
parameters passed in body
This is not happening in get method.
Use POST for destructive things such as creation, editing, and deletion.
get is used for fetching documents.
post used for updating data.
in get we pass things like customer id, uId to get a response.
post request sends information to server like customer info, file upload etc.
Check out the example of both requests.
GET Request:
GET https://api.github.com/users/{name}
Here you can pass name according to that you will get data.
GET https://api.github.com/users/sniper57
POST Request:
In this you will have to send content-type such as multipart/form-data, application/json, application/x-www-form-urlencoded and object or data that you have to pass in body.
Host: foobar.example
Content-Type: application/json
Object- [{name1:value1},{name2:value2}]
In this you are posting JSON data to API.
Comment down below if you have any queries related to get vs post methods.
A menu plays a significant role in lending an amazing UX by making an application easily navigable. It can be used to make accessibility to a particular section a breeze.If you want to ensure a surefire application, it is essential that elements of your application must be accessed with ease. It must appear intuitive and intriguing, so that users can execute them with a flair. You may create multiple modules within a project and depending upon the user’s permissions, an appropriate menu can be implemented dynamically via ASP.NET.
ASP.NET is an open source server side framework that augments web app development with great efficiency and precision. It is the core of the popular Content Management Systems (CRM), eCommerce, and so forth that deliver utile features.
Here is a comprehensive guide that offers a complete tutorial for creating a user-friendly dynamic menu via ASP.NET MVC. The process is extremely simple with only 5 easy steps at a glance.
Let’s distill the process and explore how dynamic menus can be created efficiently.
Create Dynamic Menu in ASP.NET MVC
Step 1: Create a database table
To create dynamic menus in ASP.NET MVC, the very first step is to generate a database table that can hold all the menu items in a designed hierarchy (if any). The database table can be created with a simple query as mentioned below.
Create Table Menus(ID int Primary Key Identity(1,1), ParentID int foreign key References Menus(ID), Title varchar(50), Description varchar(250))
This query will create a table Menus that will hold four values. These values are:
ID: is the primary key and auto generated Parent ID: is the foreign key Title: Name of the field Description: is the information that you want to display when a user hovers over the menu.
With this, a desired table will be created in the database.
Step 2: Insert values into the table
A simple insert query can be used for adding the data into the table. Now, there are two possibilities, that is, your menu may possess multiple parent items that further possess child items or there may be parent items only. So, you must insert the values as per your app requirements.
Query to insert values into the table Menus.
Insert Into Menus(null, ‘Item One’, ‘Desc’) // First Parent Item Insert Into Menus(null, ‘Item Two, ‘Desc’) // Second Parent Item Insert Into Menus(null, ‘Item Three’, ‘Desc’) // Third Parent Item
Insert Into Menus(1, ‘Item Sub One’, ‘Desc’) // Child of First Parent Item Insert Into Menus(2, ‘Item Sub Two’, ‘Desc’) // Child of Second Parent Item Insert Into Menus(3 ‘Item Sub Three’, ‘Desc’) // Child of Third Parent Item
By implementing the above mentioned queries, your Menus table will contain three items in the Menu and each item will further have a child item.
Step 3: Fetch the data from the table
Now, the next step is to fetch the menu items from the table Menus that was created in the step 1, and return a list of all the items.
For this, a GetMenus() function is created in MyMenu class. In this function, there is a loop that will help fetch the items of the Menu and return them via a list. The lines of code for the same is as follows.
Code Snippet for model:
publicstaticclass MyMenu { /// <summary> /// Get List of All Menu Items from Database /// </summary> /// <returns>Returns List<Menus> object</returns> publicstatic List<Menus> GetMenus() { using(var context = new ProjectEntities()) { return context.Menu.ToList(); } } }
Step 4: Display the created menu on the screen
Now, when the Menu items has been fetched from the database, it is the time to represent it in the view.
Code Snippet for View:
@{ List<Menus> myMenu = MyMenu.GetMenus(); var plist = myMenu.Where(m => m.ParentID == null).ToList(); // This will list main menu items on which we’ll apply loop to display them. if (plist != null && plist.Count > 0) { <ul class=”nav”> @foreach (var pitem in plist) { <li> <a href=”{URL-Required} title=”@Description”>@pitem.Title</a> @{ var clist = myMenu.Where(m => m.ParentID == pitem.ID).ToList(); if (clist != null && clist.Count > 0) { <ul> @foreach (var citem in clist) { <li><a href=”{URL-Required}”title=”@Description”>@citem.Title</a></li> } </ul> } } </li> } </ul> } }
Here, ui and li HTML tags are used in the loop. This will help display the created menu in the view. Now, move to the next step.
Step 5: Beautify the menu to make it appear captivating
To ensure an enticing and easily readable menu, it is essential to make it appear visually appealing and intriguing. You may use the CSS appropriately to enhance the look and feel of the menu in a desired fashion. Here, I have incorporated the following chunk of code in the CSS file to boost the navigation ease and ensure an attractive Menu.
Code Snippet CSS:
ul, ol, li {list-style: outside none none;} .nav {float: left;padding: 0;background-color: #5eab1f;} .nav li {display: inline-block;position: relative;vertical-align: middle;} .nav li:hover, .nav li.active {background-color: #4c9312;} .nav li a {color: #fff;float: left;font-size: 15px;padding: 16px 14px; text-decoration: none;} .nav li ul {background-color: #fff;border-radius: 0 0 5px 5px;box-shadow: 0 2px 3px #000;display: none;min-width: 200px;padding: 20px 0;position: absolute;top: 48px;z-index: 9999;} .nav li ul:before {border-bottom: 8px solid #fff;border-left: 8px solid transparent;border-right: 8px solid transparent;content: “”;left: 28%;position: absolute;top: -8px;} .nav ul li {float: left;width: 100%;} .nav ul li a {color: #333;float: left;font-size: 15px;padding: 10px 5%;width: 90%;} .nav li:hover, .nav li.active {background-color: #4c9312;}
This CSS has been created considering a few requirements, you may develop it in a desired fashion to bring substantial changes in the visual appearance. Therefore, you may streamline the CSS as per your UX and design needs.
Wrapping Up
By following this absolute guide, you can efficiently create beautiful dynamic menus via the ASP.NET MVC. It is advisable to thoroughly go through each step and design desirable menu while ensuring utmost navigation ease.
Many ASP.NET developer find writing and managing code for data access a monotonous job. But there is some good news. Microsoft provides an O/RM framework called Entity Framework that helps to automatically handle all your database related activities for your app, eliminating the need to write data-access plumbing code. In essence, Entity Framework helps in making your ASP.NET app easier to maintain. The Entity Framework provides three approaches that helps to connect ASP.NET application to database. These three approaches are:
Model First
Database First
Code First
In this post we will talk about Entity Framework model first approach, and to help you better understand this approach we will also create a sample ASP.NET MVC application using model first approach.
But before that, let’s first an overview of the latest 6.1 version of Entity Framework.
A Brief Introduction on Entity Framework 6
Entity Framework 6 (EF6) has introduced many new interesting features for its approaches. The latest EF 6 version works well with projects using the .NET Framework 4 (and later) and Visual Studio 2010 or later. Let us take a some of the important features of Entity Framework 6:
Dependency Resolution
Connection Resiliency
Multiple Contexts per Database
Code Based Configuration
Code First Mapping to Insert/Update/Delete Stored Procedures and many more.
In our example, we will be working on Visual Studio 2013.
Let’s Get Started
In order to create MVC 5 application with help of the Model First Approach, we’ll have to go through each one of the following sections:
Creating Web Application
Adding Entity Data Model
Working with Entity Data Model Designer
Working with Controller and Views
do CRUD Operations
Working with Database
Creating Web Application
Here, we will take an example to learn the process of creating an ASP.NET web application with help of the MVC Project Template. Follow the below mentioned steps to proceed:
Step 1: Open Visual Studio 2013 and then click on New Project.
Step 2: Click on the Web tab from the left side of the window, and then select the ASP.NET web application and assign name to the application as “ModelFirstApproach”.
Step 3: As shown in the screen shot below, you will have to choose the MVC Project Template and click on the OK button.
Visual Studio will create the MVC application automatically and add several files and folders to your project. You can check out all those files and folders from the Solution Explorer.
Adding Entity Data Model
In this section, as the name implies, we will be adding an Entity Data Model (i.e. the ADO.NET) to the application. For doing so, we will first create an empty model using the below given procedure:
Step 1: Right-click on the Models folder in the Solution Explorer, and then click on its corresponding Add option. From the Add pane click on ADO.NET Entity Data Model.
Step 2: In this step, you will need to define the model name and click on OK. In our example, we have specified the model name as “ModelFirstModel”.
Step 3: Next from the Entity Data Model Wizard, click on the Empty Model option and hit the “Finish” button.
Following the above step, you will be able to see the Entity Data Model Designer (i.e. ModelFirstModel.edmx).
Working with Entity Data Model Designer
Here, we’ll add the entity in newly created Entity Data Model Designer using two sections, as listed below:
1. Adding Entity Model
In this section, we will create the entity model by following the below given procedure.
Step 1: Right-click on the Entity Data Model Designer and click on Add New>>Entity. This will help to add new entity as follows:
Step 2: Now in the “Add Entity” wizard, specify the name of your entity.
Note: We have specified Books as our entity name, however, you can change it according to your own requirement.
Step 3: Once you’ve completed creating the entity, you’ll have to add a scalar property to it. For doing so, right-click on the Entity click on Add New>>Scalar property.
Now we’ll change the property name.
Step 4: You can choose to add even more scalar properties to the entity i.e. Books.
Note: You can create more entity models as per your requirement in the Data Model Designer.
2. Generate Database from Model
After generating an entity model, it’s time to generate the database from the model. For this purpose, simply follow the below mentioned steps:
Step 1: Right-click on the Data Model Designer space and click on the “Generate Database from Model” option.
Step 2: When the Generate Database Wizard opens, click on “New Connection” for establishing a connection with the database.
Step 3: When the Connection Properties wizard opens, you will need to assign a name to the server and the database.
Next, click on “Test Connection” to ensure whether the connection has been established or not.
Step 4: The connection with the database will be created, as you can see in the Generate Database Wizard. And then, click on the Next button.
Step 5: In this step, the database summary and script will be generated. After that, click on the “Finish” button.
Step 6: Next, right-click on the script that is being generated and click on Execute.
Clicking on execute will create the database that you can see in the Server Explorer as shown below:
Working with Controller and Views
Till now, we have worked with the database. So far we have the done the work with the database. And now we’ll be working with the controller as well as views in MVC 5. First off, we’ll use the Entity Framework to add the MVC5 Controller using the following procedure:
Step 1: We’ll have to build the solution, in order to locate the model class in the Models folder. Books class is generated in the models folder (i.e. ModelFirstModel.edmx). Simply edit the code with the highlighted code as shown in the screenshot below:
Step 2: In the Solution Explorer pane, right-click on the Controller and click on Add>>New Scaffolded Item.
Step 3: Now the Add Scaffold wizard will open. From this wizard, select the option “MVC 5 Controller with views, using the Entity Framework”.
Step 4: Now in the Add Controller Wizard, we’ll be specifying the following fields:
Controller name
Model class
Data Context class
And then, click on Add.
After clicking on the Add button, the BooksController class is generated inside the Controllers folder. In addition, the Books folder is generated within the Views folder as highlighted in the screen shot below:
Do CRUD (CReate-Update-Delete) Operations
Here we’ll be performing CRUD operations: Create, Read, Update and Delete using the following procedure:
1. In the very beginning, we will be creating an “Action Link” to our View. For this purpose, we will go to the Views>>Shared>>_Layout.cshtml file and will edit the code with the following code:
In this code, we’ve created an action link. In addition, we have edited the app name and its title.
2. Now we will be working with the CRUD operations:
2.1 Create: In this particular section we will be working on Create operation.
Step 1: First off, we’ll run the application we have created. In our application home page we’ll click on Books.
Step 2: After clicking on Books from the navigation tab, a window will open (as shown below). In this window, we’ll click on the “Create New” link for creating the record for our Books application.
Step 3: In the next window, fill all the fields (as shown below) and click on Create.
You can add as many records as you want using the same procedure. Once your record gets created, you can perform two operations on it:
2.2 Read: You can read the corresponding records, when you click on the Books link.
2.3 Update: You can update the corresponding record by following the below mentioned steps:
Step 1: Open your record you want to edit, and click on the Edit link.
Step 2: Now edit the record and hit the “Save” button.
3. Delete: You can even delete the record you’ve created, by clicking on the Delete link.
Working with Database
Now all the tables and records will be updated in the database. In order to view them using the Server Explorer, follow these steps:
Step 1: In the Server Explorer, click on the Model folder. Next, right-click on the Tables folder and click on Books>> Show Table Data.
Step 2: Now, all the records will be visible on the screen.
That’s it for now! Hope reading this tutorial will help you learn how you can create an ASP.NET MVC 5 application using EF model first approach.



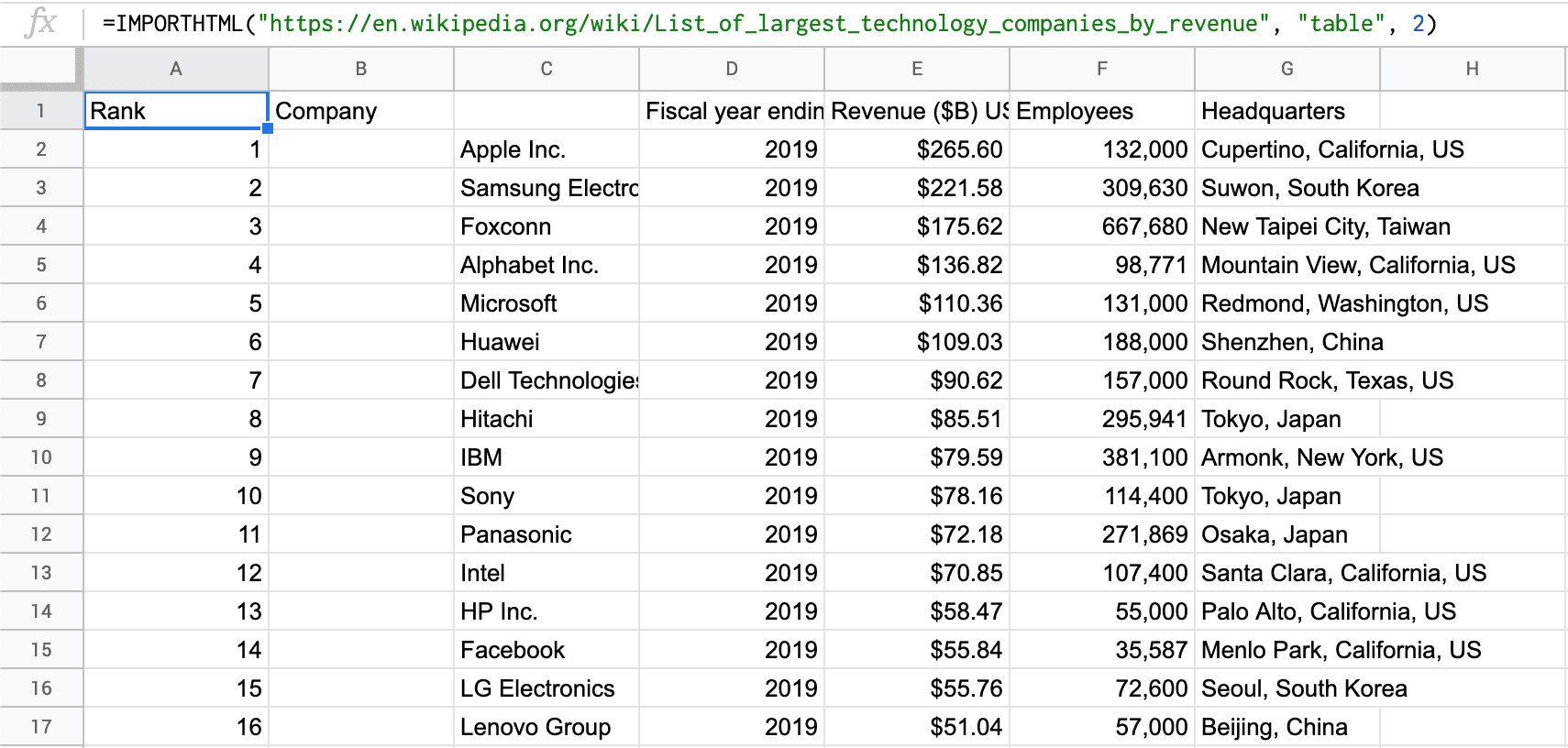


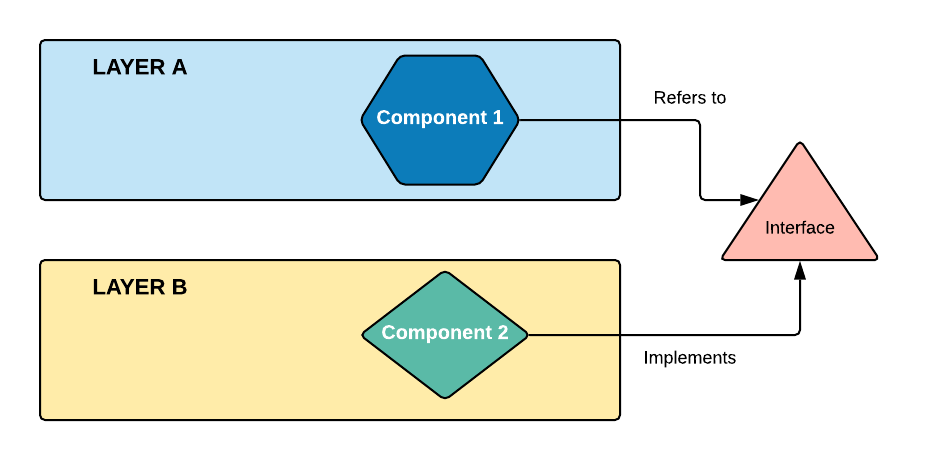
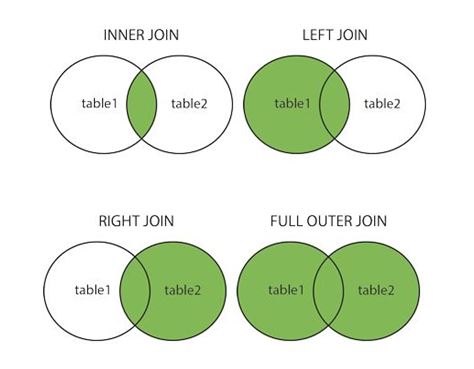













.png)